
Was ist die robots.txt Datei?
Die robots.txt ist eine kleine Textdatei, die im Hauptverzeichnis einer Website liegt – meist einfach unter/robots.txt. Ihre Aufgabe: Sie gibt Suchmaschinen Hinweise darauf, welche Seiten oder Bereiche der Website sie crawlen dürfen und welche nicht. Sie ist also so etwas wie ein digitaler Türsteher: freundlich, höflich, aber bestimmt.
Die Datei folgt einem einfachen Prinzip: Sie spricht gezielt sogenannte User-Agents an (z. B. Googlebot oder Bingbot) und gibt ihnen Anweisungen. Dabei ist sie technisch nicht bindend – Suchmaschinen könnten sich darüber hinwegsetzen. Seriöse Crawler wie der Googlebot tun das aber in der Regel nicht. Wer also seine Seite im Griff haben will, sollte die robots.txt beherrschen – und spätestens bei einem umfassenden SEO-Audit einen genauen Blick darauf werfen.
Warum ist die robots.txt so wichtig?
 Die Datei kann entscheidend dafür sein, wie gut und wie schnell eine Website indexiert wird. Gerade große oder dynamische Websites profitieren davon, denn Suchmaschinen haben nur ein begrenztes Crawl-Budget pro Seite. Wenn Ressourcen auf irrelevante oder technische Seiten verschwendet werden, bleiben die wichtigen Inhalte womöglich außen vor.
Ein gutes Beispiel: In einem SEO-Check zeigt sich oft, dass zahllose unnötige URL-Varianten indexiert werden – etwa von Filtern, internen Suchergebnissen oder Plugins. Eine gezielt eingesetzte robots.txt kann das verhindern und so helfen, den Fokus der Suchmaschine auf hochwertige Seiten zu lenken.
Die Datei kann entscheidend dafür sein, wie gut und wie schnell eine Website indexiert wird. Gerade große oder dynamische Websites profitieren davon, denn Suchmaschinen haben nur ein begrenztes Crawl-Budget pro Seite. Wenn Ressourcen auf irrelevante oder technische Seiten verschwendet werden, bleiben die wichtigen Inhalte womöglich außen vor.
Ein gutes Beispiel: In einem SEO-Check zeigt sich oft, dass zahllose unnötige URL-Varianten indexiert werden – etwa von Filtern, internen Suchergebnissen oder Plugins. Eine gezielt eingesetzte robots.txt kann das verhindern und so helfen, den Fokus der Suchmaschine auf hochwertige Seiten zu lenken.
So ist meine eigene robots.txt aufgebaut
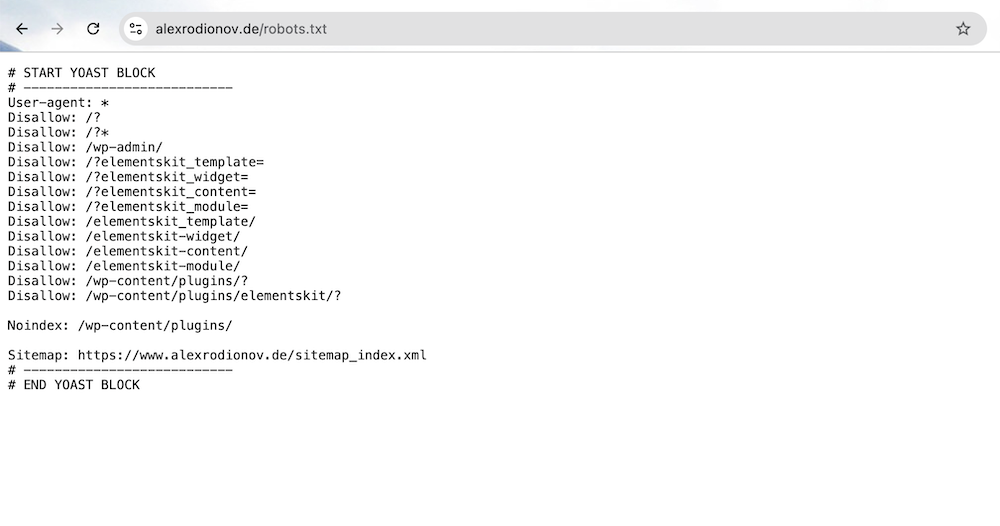
Um dir ein konkretes Bild zu geben, zeige ich dir hier den aktuellen Stand meiner eigenen robots.txt. Diese Version schützt technische Seiten, blockiert nutzlose Parameter-URLs und weist gleichzeitig auf die Sitemap hin:# START YOAST BLOCK
User-agent: *
Disallow: /?
Disallow: /?*
Disallow: /wp-admin/
Disallow: /?elementskit_template=
Disallow: /?elementskit_widget=
Disallow: /?elementskit_content=
Disallow: /?elementskit_module=
Disallow: /elementskit_template/
Disallow: /elementskit-widget/
Disallow: /elementskit-content/
Disallow: /elementskit-module/
Disallow: /wp-content/plugins/?
Disallow: /wp-content/plugins/elementskit/?
Noindex: /wp-content/plugins/
Sitemap: https://www.alexrodionov.de/sitemap_index.xml
# END YOAST BLOCK
<meta name="robots" content="noindex">-Tag auf der Seite selbst arbeiten. Trotzdem findet man die Zeile noch häufig – etwa aus Gründen der Kompatibilität mit Dritt-Tools.
Die wichtigsten Anweisungen im Überblick
- User-agent: Bestimmt, für welchen Crawler die Regel gilt (z. B.
*für alle Bots oderGooglebotgezielt für Google) - Disallow: Gibt an, welche Verzeichnisse oder Seiten nicht gecrawlt werden dürfen
- Allow: (optional) Gibt Seiten frei, auch wenn übergeordnete Bereiche blockiert sind
- Sitemap: Verlinkt zur XML-Sitemap, damit Google die wichtigsten Inhalte direkt findet
Damit lässt sich bereits sehr viel kontrollieren. Besonders bei Websites mit vielen automatisch generierten URLs – etwa durch Filter, interne Suchfunktionen oder Plugins – kann eine saubere robots.txt die Indexierung deutlich verbessern.
Was die robots.txt nicht kann
Ein häufiger Irrtum ist, dass man mit der Datei Seiten komplett „unsichtbar“ machen kann. Das stimmt so nicht. Die robots.txt verhindert nur das Crawlen, nicht aber die Indexierung – zumindest nicht automatisch. Google kann eine nicht gecrawlte Seite trotzdem im Index aufnehmen, etwa wenn andere Seiten darauf verlinken. Wer Inhalte wirklich aus dem Index ausschließen will, sollte stattdessen:- die Seite mit
<meta name="robots" content="noindex">versehen - sie aus der Sitemap entfernen
- oder per Authentifizierung / .htaccess-Zugriffsschutz absichern
Typische Anwendungsfälle
Die robots.txt eignet sich besonders gut für den Ausschluss folgender Bereiche:- /wp-admin/ oder andere Admin-Bereiche
- Dynamische Filter-URLs und Parameter-Varianten
- Interne Suchergebnisseiten
- Seiten von Plugins und Themes
Was passiert, wenn sie fehlt?
Falls keine robots.txt vorhanden ist, crawlt Google einfach alles, was technisch zugänglich ist. Das kann okay sein – muss es aber nicht. Gerade bei Relaunches, A/B-Tests oder instabilen Seiten kann das zu Problemen führen. Auch der Server kann überlastet werden, wenn Google zu aggressiv crawlt. Im schlimmsten Fall indexiert die Suchmaschine Inhalte, die gar nicht für die Öffentlichkeit gedacht sind. Daher: Auch wenn man (noch) keine Regeln definieren will – eine leere Datei ist besser als keine Datei. Und spätestens bei einem professionellen Setup mit laufender SEO-Betreuung gehört die Datei zur Grundausstattung.Wie testet man die robots.txt richtig?
Am besten mit der Google Search Console. Dort gibt es im Bereich „Crawling“ eine Funktion zum Testen der Datei. Außerdem kann man dort erkennen, ob wichtige Seiten blockiert sind – oder ob Google versucht, URLs zu crawlen, die gar nicht mehr existieren. Zusätzlich helfen Tools wie Screaming Frog oder Sitebulb bei der lokalen Analyse. Wer regelmäßig Änderungen an der Website durchführt, sollte die Datei in den Workflow integrieren und regelmäßig prüfen. Genau das ist übrigens auch Teil einer fundierten Arbeit als SEO Freelancer – technische Kontrolle, bevor Probleme entstehen.Fazit: Kleine Datei, große Wirkung
Die robots.txt ist ein einfacher, aber mächtiger Bestandteil jeder Website. Sie entscheidet mit darüber, wie Suchmaschinen deine Inhalte wahrnehmen – und ob sie im Index landen oder nicht. Wer damit sorgfältig arbeitet, spart Crawl-Budget, schützt vertrauliche Bereiche und sorgt für bessere Rankings. Und das Beste: Die Datei ist schnell eingerichtet. Ein Texteditor reicht. Trotzdem lohnt sich der Blick ins Detail – vor allem, wenn man mit SEO langfristig erfolgreich sein will. Wer sich nicht sicher ist, lässt die Datei im Rahmen eines Audits oder eines strukturierten SEO-Checks prüfen – oder holt sich gleich Unterstützung von einem Profi. Weitere Infos gibt’s im offiziellen Leitfaden von Google, der viele Beispiele und Sonderfälle erklärt – ideal für alle, die ein bisschen tiefer einsteigen wollen.
Welche Keyword-Art in Google Ads im Jahr 2026 am sinnvollsten ist
Welche Keyword-Art funktioniert in Google Ads 2026? Erfahrungen aus Konten mit genau passenden Keywords, passender Wortgruppe, weitgehend passend.

Performance Max 2026. Was ändert sich? Das ultimative Guide
Performance Max 2026: Kanalleistung-Bericht, Text Guidelines, Placement-Bericht. Ultimativer Guide mit Praxistipps aus +10 Mio. € verwaltetem Budget.

Online Marketing News März 2026
Das sind die Online Marketing News März 2026: ChatGPT Ads in den USA, Discover-Update, neue Google-Limits und KI in der Search Console im Überblick.
Conversions maximieren bei Google Ads – Wann lohnt es sich?
Conversions maximieren ist eine Google Ads Gebotsstrategie mit klarer Datenabhängigkeit. Erfahrt, wann sie funktioniert und wann Vorsicht geboten ist.